웹 크롤러란?
웹 스크래핑, 웹 스파이더 등으로 부른다. 크롤러가 하는 일을 크롤링 - 스파이더링이라 한다.
다른 웹에서 정보를 긁어 와 자동적으로 최신형태로 유지할 때 자주 사용되게 된다.
간단한 예제를 바로 시작해보자
- 오피셜한 Nokogiri 사이트 : http://www.nokogiri.org/ 에 들어가면 튜토리얼과 설치법이 있음
- 저는 제 블로그의 제목과 내용을 한번 크롤링 해보겠습니다. https://hanjungv.github.io/
설치하기
- 먼저 저는 루비마인을 이용합니다. 그냥 아톰을 이용하시는 분이라면 터미널에서 rails new 를 해서 프로젝트를 만들어주세요.
- nokogiri gem을 추가해 주고 bundle install을 해줍니다. 그냥 gem install nokogiri 를 해줘도 됩니다.
$ gem install nokogiri
- 그리고 컨트롤러와 크롤링 한 내용을 담을 모델을 만들었습니다.
$ rails g controller home crawler
$ rails g model result title:string content:text
model
class CreateResults < ActiveRecord::Migration
def change
create_table :results do |t|
t.string :title
t.text :content
t.timestamps null: false
end
end
end
Controller
- 먼저 제 블로그를 살펴 보겠습니다.
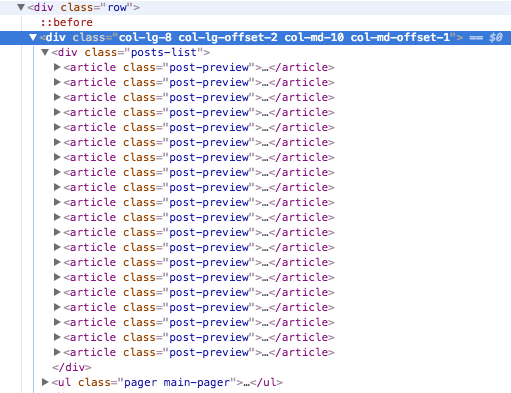
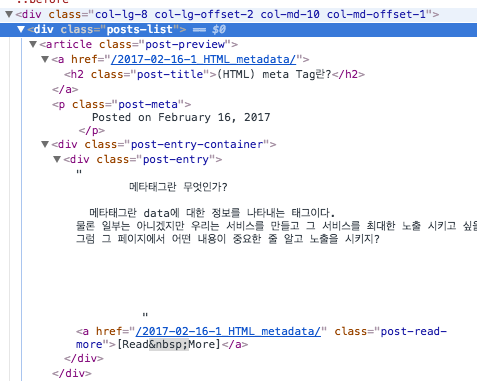
- 제목은 post-preview 내부에 h2에 담겨있고 미리보기는 post-entry에 담겨있네요.
- 그리고 제 블로그는 총 2페이지로 구분되어 있고 /page로 페이지네이션을 했습니다.
require 'open-uri'
class HomeController < ApplicationController
def crawler
(2).downto(1) do |c| #반복문을 돌면서
if c == 1
addPage = ""
else
addPage = "page#{c}/"
end
url = "https://hanjungv.github.io/" + addPage # url을 지정해
doc = Nokogiri::HTML(open(url)) # 열고
@posts = doc.css('.posts-list article') #article 클래스를 갖는 객체들을 전부 post에 담아
@posts.each do |x| #각각 돌면서 Result에 추가해줍니다.
tit = x.css('.post-title').text.strip
cont = x.css('.post-entry-container .post-entry').text.strip
@res = Result.new(title: tit, content: cont)
@res.save
end
end
redirect_to '/'
end
def show
@pr = Result.all
end
end
View
<!--테이블로 뽑혀오는 데이터를 출력해 봤습니다.-->
<table>
<thead>
<tr>
<td>제목</td>
<td>내용</td>
</tr>
</thead>
<tbody>
<%@pr.each do |p|%>
<tr>
<td><%= p.title %></td>
<td><%=p.content%></td>
</tr>
<%end%>
</tbody>
</table>
<a href = '/home/crawler'>크롤링하기</a>
결과화면

- 해당 문서를 잘 파악하고 뽑아낼 위치만 잘 찾아된다면 어렵지 않게 크롤링 할 수 있습니다.
- 그나저나 Nokogiri는 정말 쉽게 크롤링 할 수 있게 도와주는군요..